Language Modelling
Implementation of Language Models from Scratch & The Intuition behind
What is a Language Model & Why do we need it?
In NLP, our fundamental goal is to be able to estimate probability distribution over possible words/sentences. If we can do that, we would be able to assign a likelihood for a given sentence. Hence, can also derive Maximum Likelihood Estimates of our statistical models’ parameters.
Also, we would be able to sample from those distributions of words/sentences for generating text or predicting probability of text.
Task of finding probability distribution over word sequences is called Language Modelling and we will be expressing this mathematically for a single sentence as an example below and will be going through the ways of language modelling based on that example in the upcoming sections & Posts.
For example, assume we have a huge corpus of text with billions of tokens — common examples are CNN/Daily Mail, GLUE, SQUAD etc.— and we want to estimate the probability of observing the sentence “Better late than never.”

Applying chain rule of probability

N-Gram Model
N-gram is a simple language model that models the language as a Markov process. Markov chain makes a naive assumption about the language and assumes that probability of observing each word in the language only depends on the previous word in the sentence. N-gram extends this assumption and assumes dependence up to previous n-1 words.
Based on this assumption, if we adapt the above equation to n=2 case in other words bigram model, we end up with simplified version as follows;

Now we need to find a way to estimate above 4 conditional probabilities — In fact, we need to find the probability distribution over all the words in the language for any given conditional word to be able to calculate likelihood of any sentence as we will end up converting any sentence to the above format.
We will be implementing one analytical method and one iterative method for estimating those probability distributions below and see how they are different in the way that they handle the problem described above.
Analytic Solution — Maximum Likelihood Approach
Maximum Likelihood approach structures the problem in a way that we look for the probabilities that maximizes the likelihood of our training set and luckily we have a closed-form mathematical solution for that which we can plug in and get the estimates of those conditional probabilities — we won’t be getting into the derivation of this but it is certainly a fundamental aspect of statistical models which I would recommend to get familiar with if you haven’t yet.
This is based on co-occurrence and probability estimates of each component above can be found analytically using Maximum Likelihood Estimates — which would be the conditional probabilities described above in the training set. For example;

Implementation
Now, we can start implementing the code that will estimate the required probability distributions. You can find the small python package that I prepared for this and the next task and the repo.
- First, we start with implementing a method to encode words as index and add extra special tokens as
<S>for the start of a sentence,</S>for representing the end of a sentence and<UNK>for representing the potential words that exists in the test data but not in the training data.
- Then we create the co-occurrence matrix of words and divide each occurrence by the total number of occurrences of the conditioned word as shown in the above example for word ‘late’ and we calculate
self.Pin the__init__method.
- Now we have the conditional probability estimates of each combination of words / word sequences. To generate text from this simple language model we can randomly sample from that probability distribution defined using the method below.
Iterative Solution — Neural Network
Again, main idea in language modelling is coming up with estimates of those probabilities and another method which is not analytical but iterative is estimating those conditional probabilities with the help of a Neural Network.
In this case, we structure the problem in a way that we will be defining a loss function that represents our training purpose and will optimize it by tweaking our neural network parameters. Hence, our purpose becomes learning neural network parameters that leads to a lower value of loss function which leads to an accurate (based on the probability distributions in training data of course) estimate of the conditional probability distributions.
Then the question becomes, how we will quantify the similarity between predicted probability distribution and the training set probability distribution? And the answer is a super common function in deep learning — Cross Entropy
Cross Entropy
By definition Cross entropy is a measure of the difference between two probability distributions for given two random variables following P and Q probability distributions. Below is the definition of cross entropy.
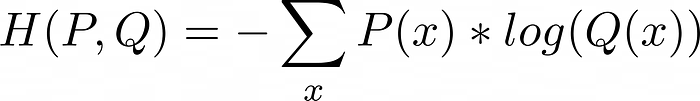
Note: It is good to keep in mind that
H(P,Q)andH(Q,P)are not equal so a bit confusing for a distance measure.
It also has a different meaning in information theory which I won’t be mentioning here but would recommend taking a look at this article that explains it all.
It is a super common loss function in Deep learning because it let us quantify the accuracy of the predictions comparing the predicted probability distributions and the ones observed in training set.
Cross-Entropy as a Loss Function & Relationship with Maximum Likelihood
Using cross-entropy as a loss function is a special case because predicted probability distribution is actually distributed over possible outcomes, but the label distribution has only 1 outcome with probability of 1 for each example. Hence, P(x) — which represents the label distribution — in above formula has the value of 0 except for the correct label so we can get rid of the summation and only calculate log(Q(x)) which is the predicted probability for the correct class — in our example it will be the predicted probability of the correct next word.
— And yes, for a single instance, it is just negative log-likelihood!
Hence, cross entropy is equivalent to Average Negative Log Likelihood when used as a loss function.
Implementation
We will be implementing the Neural Network for the n-gram language modelling task below using PyTorch. This part of the code also exists in the same repo I put together.
- In this case, we inherited from Dataset class of PyTorch and structure our dataset in a way that we have a tensor for predictors i.e.
xand another tensor for labels i.e.y. The main difference in terms of we structure the data for the training is that we don’t use co-occurrence matrix this time.
- Then, we implement the Neural Network architecture and the training function. This time we go with a very simple architecture of one Embedding layer for deriving dense representations of word vectors and pass those representations through a linear layer and a cross-entropy loss finally and calculate the gradients and make the backward pass.
Now once we done with training, we have a Neural network that takes our input text and gives and estimated probability distribution of the next word which means we can generate samples from that distribution just like we did in the Maximum Likelihood approach.
Concept Of Auto-Regression
Auto-regressive methods involves sampling next instance — next word in our case — based on the estimated probability distribution and then using that sample to estimate the probability distribution of the word after it just like we applied in our example for sampling. There are also non-auto-regressive methods exist, but auto-regression is known to be producing higher quality samples. Auto-regressive methods usually involves using more intelligent search methods over the generated probability distributions — What we implemented is the base logic behind it, one example would be use of beam-search algorithm in sampling process.
Conclusion
In this post, I tried to explain one of the simplest ways for language modelling. I am planning to convert those posts into a series of language models theory & implementations covering the more advanced models like transformer-based ones.
Main difference between language models is Neural Network architecture used and the way the loss calculated (even though ‘language modelling’ itself refers to a certain way of calculating the loss). In this case We used N-gram language model — referring the way we calculated loss based on the previous n-1 words — and we implemented that using a simple Neural Network architecture which is Multi-Layer Perceptron.
